XSS and SQLi Scanning with mitmproxy
As of last week, mitmproxy now has built in support for detecting cross site scripting and SQL injection vulnerabilities. To have mitmproxy automatically scan pages for XSS and SQLi vulnerabilities, simple run it with the included xss_scanner.py script like so:
mitmproxy -s xss_scanner.py
From there, it will run the xss.py script on every page that you visit through mitmproxy's proxy. It looks for vulnerabilities in the page by injecting a payload, 1029zxcs'd"ao<ac>so[sb]po(pc)se;sl/bsl\3847asd3847asd, into four different places:
- The end of the URL. For example, the URL
https://example.comis turned intohttps://example.com/1029zxcs'd"ao<ac>so[sb]po(pc)se;sl/bsl\3847asd3847asd. This is generally effective at finding XSS vulnerabilities that involve pages including the current URL somewhere in the page. - The referer header. A lot of the time websites will have a built in "back" button (for example on 404 pages) that can lead to XSS vulnerabilities.
- The user agent. Often times pages will include user agents in the HTML as debugging information for any errors.
- Queries. This is the broadest of the categories, but some of the most common examples of an XSS from injecting into the query string are search bars or usernames.
The script then looks for those strings in the webpages and checks whether or not certain characters are escaped. For example, if >, >, and " are not being escaped and the HTML contains something like <img src="https://example.com/PAYLOAD"> then there would be an XSS vulnerability through injecting "><script>alert(0)</script>. In addition, the script also looks for script URLs pointed to unclaimed URLs (for example <script src="https://unclaimedDomain.com"></script>.
The script can detect over a half dozen different ways of injecting Javascript payloads. Whenever it finds a way of injecting Javascript, it displays a report to the mitmproxy console with all of the information needed to exploit the XSS vulnerability:
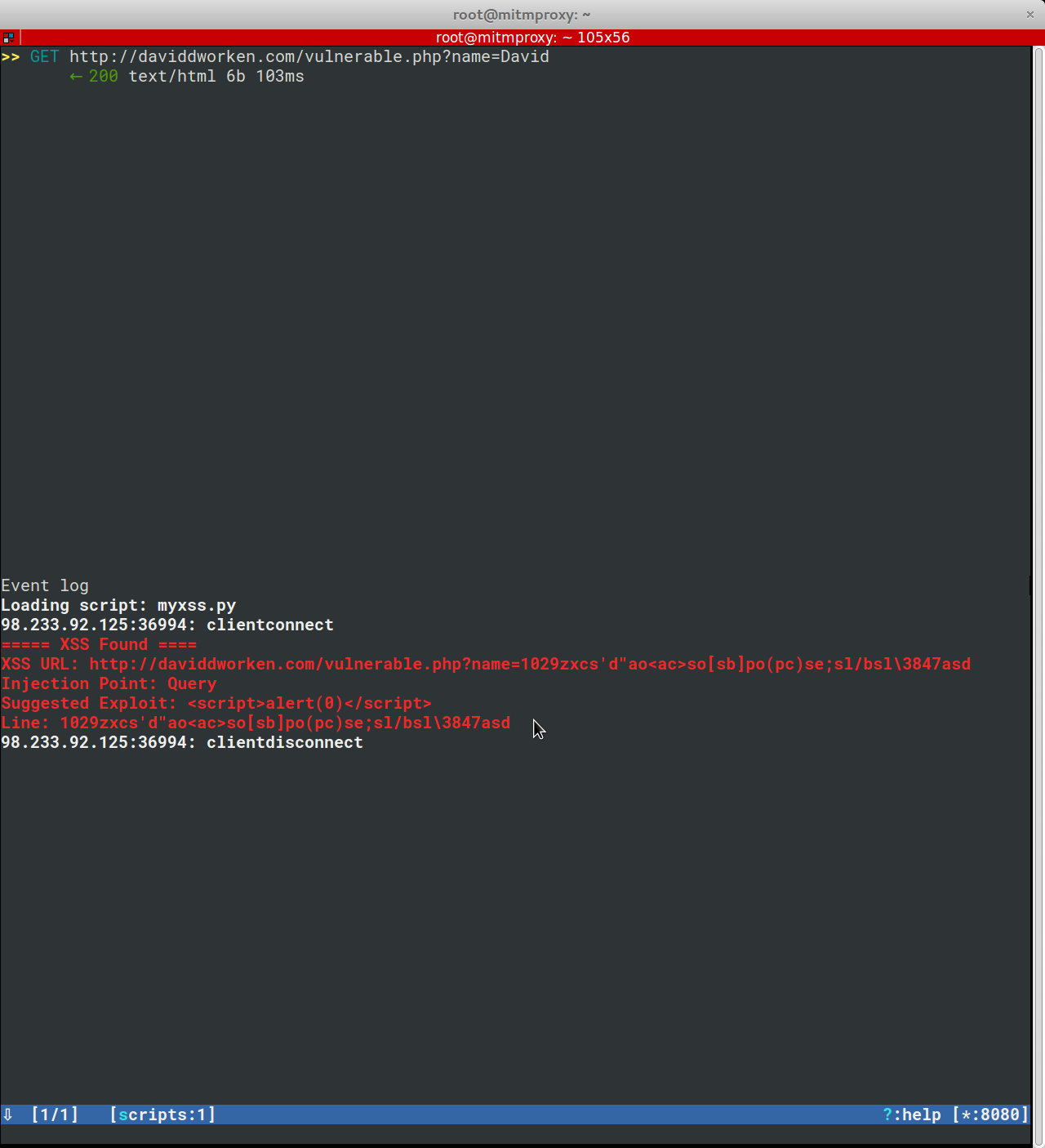
It also can detect SQLi through looking for SQL errors that appear in a page after injection of the payload. This is done using the regexes included in Damn Small SQLi Scanner.
One huge advantage to having a XSS and SQLi scanner integrated with mitmproxy is that mitmproxy has access to your cookies, so all requests are automatically made with the correct cookies for each website.
This is the first step in building out a scanning interface for mitmproxy and is going to be built upon over time to add more robust detection, better outputs, and automatic spidering. In addition, I'm currently working on building a CSRF scanner to include in the script. See the code for more information.












